Git简介
概述
关于版本控制
什么是“版本控制”,为什么你应该关心它?版本控制是一种记录文件或文件集随时间变化的系统,以便你以后可以调用特定版本。对于本书中的示例,你将使用软件源代码作为受版本控制的文件,但实际上你可以对计算机上的几乎任何类型的文件执行此操作。
如果您是平面或网页设计师,并且想要保留图像或布局的每个版本(您肯定想要这样做),那么使用版本控制系统 (VCS) 是非常明智的选择。它允许您将选定的文件恢复到以前的状态,将整个项目恢复到以前的状态,比较一段时间内的变化,查看谁最后修改了可能导致问题的内容,谁在何时引入了问题,等等。使用 VCS 通常还意味着如果您搞砸了事情或丢失了文件,您可以轻松恢复。此外,您只需很少的开销即可获得所有这些。
本地版本控制系统
许多人选择的版本控制方法是将文件复制到另一个目录(如果他们聪明的话,也许是一个带有时间戳的目录)。这种方法非常常见,因为它非常简单,但也非常容易出错。很容易忘记你在哪个目录中,并意外写入错误的文件或复制你不想复制的文件。
为了解决这个问题,程序员很久以前就开发了本地 VCS,它有一个简单的数据库,可以保存对文件的所有更改的修订控制。
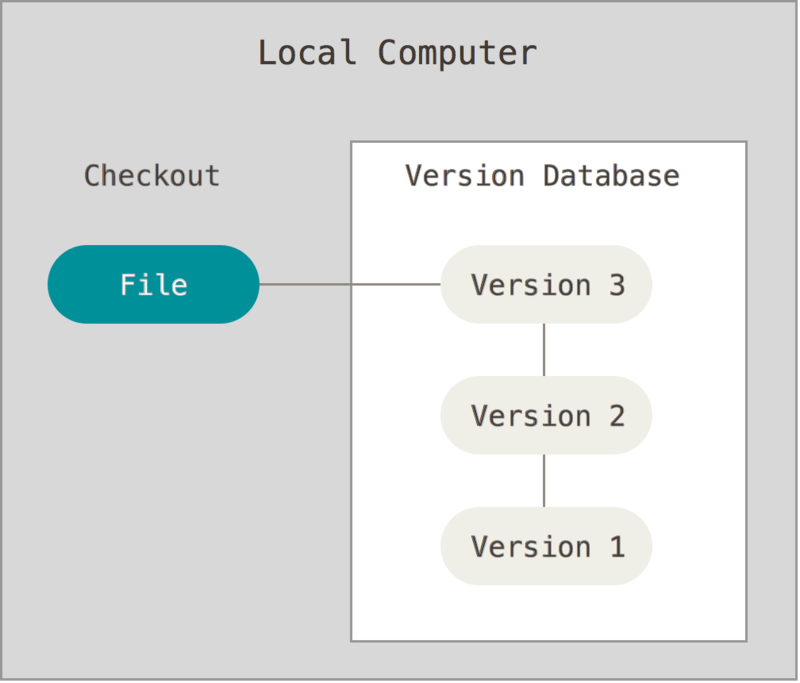
图1.本地版本控制图
最流行的 VCS 工具之一是名为 RCS 的系统,如今它仍然分布在许多计算机中。RCS 的工作原理是将补丁集(即文件之间的差异)以特殊格式保存在磁盘上;然后它可以通过将所有补丁加在一起来重新创建任何文件在任何时间点的样子。
集中式版本控制系统
人们遇到的下一个主要问题是他们需要与其他系统上的开发人员合作。为了解决这个问题,开发了集中版本控制系统 (CVCS)。这些系统(例如 CVS、Subversion 和 Perforce)有一个包含所有版本文件的单一服务器,以及从该中心位置签出文件的多个客户端。多年来,这一直是版本控制的标准。
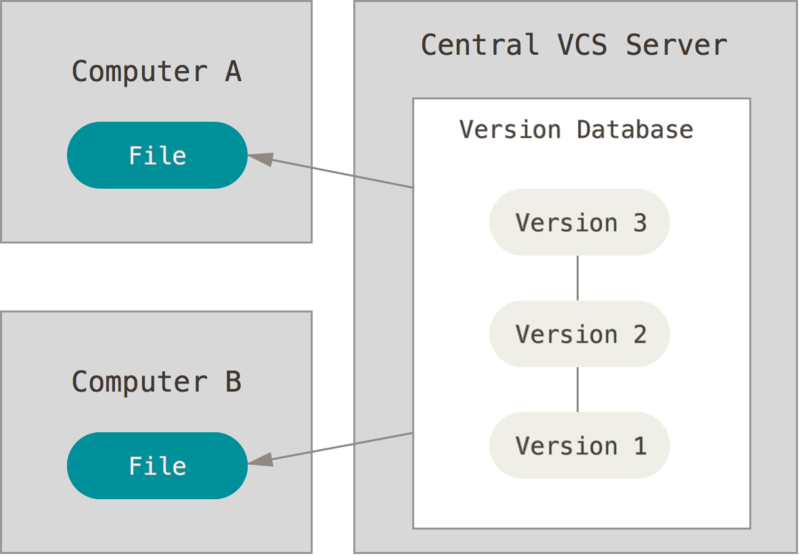
图2.集中式版本控制图
此设置具有许多优势,尤其是与本地 VCS 相比。 例如,每个人都在一定程度上知道项目中的其他人在做什么。 管理员可以精细地控制谁可以执行哪些操作,并且管理 CVCS 比处理每个客户端上的本地数据库要容易得多。
但是,这种设置也有一些严重的缺点。 最明显的是集中式服务器所代表的单点故障。 如果该服务器宕机一个小时,那么在那个小时内,任何人都无法协作或将版本化更改保存到他们正在处理的任何内容。 如果中央数据库所在的硬盘损坏,并且没有保留适当的备份,那么您绝对会丢失所有内容 — 项目的整个历史记录,除了人们碰巧在本地计算机上拥有的任何单个快照。 本地 VCS 也遇到同样的问题 — 只要您将项目的整个历史记录放在一个地方,就有可能丢失所有内容。
分布式版本控制系统
这就是分布式版本控制系统 (DVCS) 的用武之地。 在 DVCS(例如 Git、Mercurial 或 Darcs)中,客户端不仅会签出文件的最新快照;相反,它们完全镜像存储库,包括其完整的历史记录。 因此,如果任何服务器宕机,并且这些系统通过该服务器进行协作,则可以将任何客户端存储库复制回服务器以恢复它。 每个克隆实际上是所有数据的完整备份。
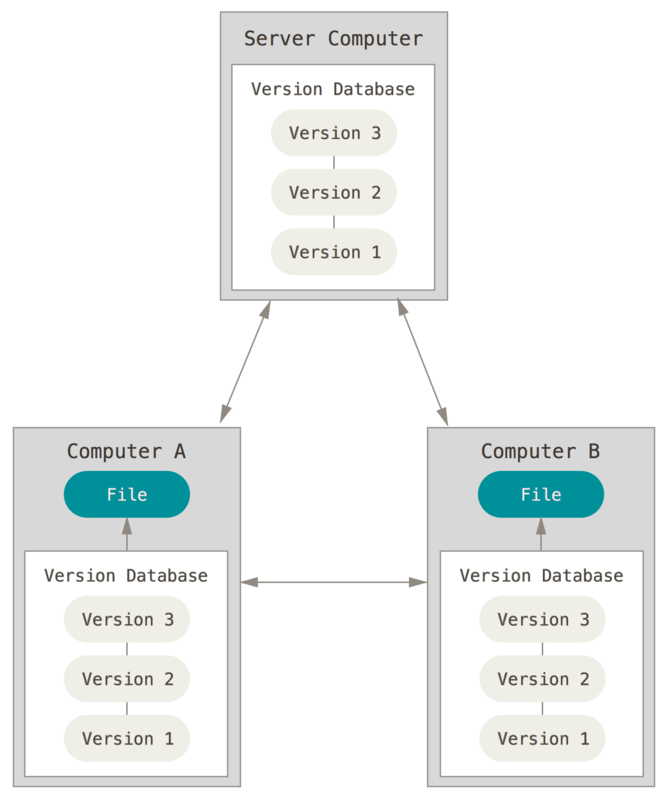
图3.分布式版本控制图
此外,其中许多系统都很好地处理了可以使用多个远程存储库的问题,因此您可以在同一项目中以不同的方式同时与不同的人群协作。 这允许您设置多种类型的工作流,这些工作流在集中式系统中是不可能的,例如分层模型。
Git历史简述
与生活中的许多伟大事物一样,Git 始于一些创造性的破坏和激烈的争议。
Linux 内核是一个范围相当大的开源软件项目。 在 Linux 内核维护的早期(1991-2002 年),对软件的更改以补丁和存档文件的形式传递。 2002 年,Linux 内核项目开始使用名为 BitKeeper 的专有 DVCS。
2005 年,开发 Linux 内核的社区与开发 BitKeeper 的商业公司之间的关系破裂,该工具的免费状态被撤销。 这促使 Linux 开发社区(尤其是 Linux 的创建者 Linus Torvalds)根据他们在使用 BitKeeper 时学到的一些经验来开发自己的工具。 新系统的一些目标如下:
- 速度
- 简单的设计
- 强大支持非线性开发(数千个并行分支)
- 完全分布式
- 能够高效处理 Linux 内核等大型项目(速度和数据大小)
自 2005 年诞生以来,Git 已经发展和成熟,易于使用,同时保留了这些初始品质。 它的速度非常快,对大型项目非常高效,并且它有一个令人难以置信的非线性开发分支系统(参见 Git 分支)。
什么是Git?
那么,简单地说,Git 究竟是怎样的一个系统呢? 请注意接下来的内容非常重要,若你理解了 Git 的思想和基本工作原理,用起来就会知其所以然,游刃有余。 在学习 Git 时,请尽量理清你对其它版本管理系统已有的认识,如 CVS、Subversion 或 Perforce, 这样能帮助你使用工具时避免发生混淆。尽管 Git 用起来与其它的版本控制系统非常相似, 但它在对信息的存储和认知方式上却有很大差异,理解这些差异将有助于避免使用中的困惑。
直接记录快照,而非差异比较
Git 和其它版本控制系统(包括 Subversion 和近似工具)的主要差别在于 Git 对待数据的方式。 从概念上来说,其它大部分系统以文件变更列表的方式存储信息,这类系统(CVS、Subversion、Perforce 等等) 将它们存储的信息看作是一组基本文件和每个文件随时间逐步累积的差异 (它们通常称作 基于差异(delta-based) 的版本控制)。
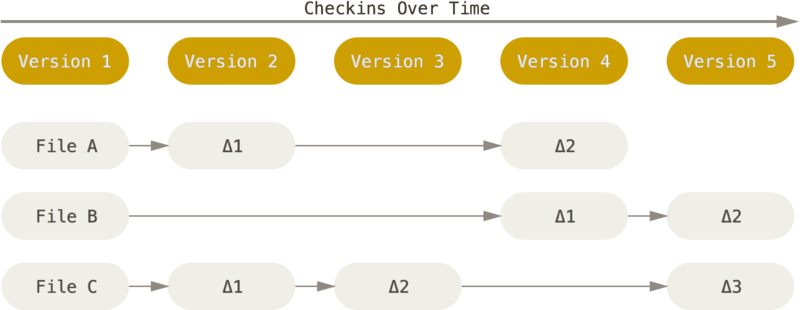
图4.存储每个文件与初始版本的差异
Git 不会以这种方式思考或存储数据。 相反,Git 将其数据更像是微型文件系统的一系列快照。 使用 Git,每次你提交或保存项目的状态时,Git 基本上都会拍摄所有文件在那一刻的样子,并存储对该快照的引用。 为了提高效率,如果文件没有更改,Git 不会再次存储该文件,而只是指向它已经存储的上一个相同文件的链接。 Git 将其数据更像是快照流。
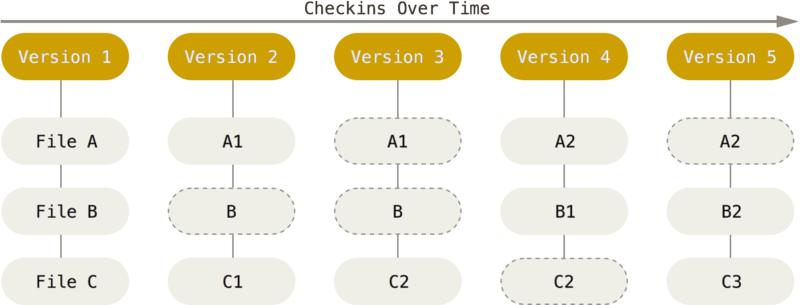
图5.随时间推移将数据存储为项目的快照
这是 Git 与几乎所有其他 VCS 之间的重要区别。 它使 Git 重新考虑了大多数其他系统从上一代复制的版本控制的几乎所有方面。 这使得 Git 更像一个迷你文件系统,在其上构建了一些非常强大的工具,而不仅仅是一个 VCS。 当我们在 Git 分支中介绍 Git 分支时,我们将探讨以这种方式考虑数据所获得的一些好处。
几乎每个操作都是本地的
Git 中的大多数操作只需要本地文件和资源即可运行,通常不需要网络上另一台计算机提供的信息。 如果你习惯了大多数操作都有网络延迟开销的 CVCS,那么 Git 的这一方面会让你认为速度之神赋予了 Git 超凡脱俗的力量。 因为您在本地磁盘上拥有项目的整个历史记录,所以大多数操作似乎几乎是即时的。
例如,要浏览项目的历史,Git 不需要去服务器获取历史并为你显示它——它只是直接从你的本地数据库中读取它。 这意味着您几乎可以立即看到项目历史记录。 如果你想查看当前版本的文件和一个月前的文件之间引入的更改,Git 可以查找一个月前的文件并进行本地差异计算,而不必要求远程服务器执行此操作或从远程服务器拉取旧版本的文件在本地执行。
这也意味着如果您处于离线或离线 VPN,几乎没有什么不能做的。 如果你坐上飞机或火车,想做一点工作,你可以愉快地提交(记住你的本地副本吗?),直到你连接到网络连接上传。 如果您回家后无法让您的 VPN 客户端正常工作,您仍然可以工作。 在许多其他系统中,这样做要么是不可能的,要么是痛苦的。 例如,在 Perforce 中,当您未连接到服务器时,您就无法执行太多操作;在 Subversion 和 CVS 中,您可以编辑文件,但不能将更改提交到数据库(因为您的数据库处于脱机状态)。 这似乎没什么大不了的,但您可能会惊讶于它可以产生如此大的不同。
Git 具有完整性
Git 中的所有内容在存储之前都会进行校验和计算,然后由该校验和引用。 这意味着在 Git 不知道的情况下,不可能更改任何文件或目录的内容。 此功能内置于 Git 的最低级别,是其理念不可或缺的一部分。 您不能在 Git 无法检测到信息的情况下丢失传输中的信息或文件损坏。
Git 用于此校验和的机制称为 SHA-1 哈希。 这是一个由十六进制字符(0-9 和 a-f)组成的 40 个字符的字符串,并根据 Git 中文件或目录结构的内容进行计算。 SHA-1 哈希值如下所示:
24b9da6552252987aa493b52f8696cd6d3b00373你会在 Git 中到处看到这些哈希值,因为它经常使用它们。 事实上,Git 不是通过文件名而是通过其内容的哈希值来存储其数据库中的所有内容。
Git 通常只添加数据
当您在 Git 中执行操作时,几乎所有操作都只向 Git 数据库添加数据。 很难让系统执行任何不可撤消的操作或使其以任何方式擦除数据。 与任何 VCS 一样,您可能会丢失或弄乱尚未提交的更改,但是在将快照提交到 Git 后,很难丢失,尤其是在您定期将数据库推送到另一个存储库时。
这使得使用 Git 成为一种乐趣,因为我们知道我们可以进行实验,而不会有严重搞砸事情的危险。 要更深入地了解 Git 如何存储其数据以及如何恢复似乎丢失的数据,请参阅撤消操作。
四种状态
现在注意 — 如果你想让其余的学习过程顺利进行,这是关于 Git 需要记住的主要事情。 Git 有四种主要状态,您的文件可以驻留:Untracked、Unmodified、Modified、Staged 和 committed:
- 未跟踪(Untracked): 文件未被纳入版本控制,Git 不会跟踪其变化。
- 已修改(Modified):文件已更改,但还未提交到暂存区。
- 已暂存(Staged):修改后的文件已放入暂存区,准备提交。
- 已提交(Committed):文件的修改已提交到本地仓库。
这让我们进入了 Git 项目的三个主要部分:工作树、暂存区域和 Git 目录。
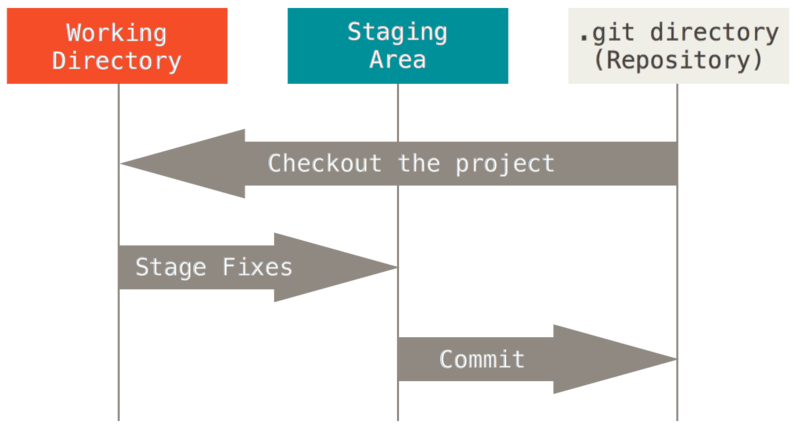
图6.工作树、暂存区域和 Git 目录
工作树是项目的一个版本的单个签出。 这些文件从 Git 目录中的压缩数据库中提取出来,并放置在磁盘上供您使用或修改。
暂存区域是一个文件,通常包含在 Git 目录中,用于存储有关下一次提交的内容的信息。 在 Git 用语中,它的技术名称是 “index”,但短语 “staging area” 也同样有效。
Git 目录是 Git 存储项目的元数据和对象数据库的位置。 这是 Git 中最重要的部分,也是从另一台计算机克隆存储库时复制的内容。
基本的 Git 工作流程是这样的:
- 您可以修改工作树中的文件。
- 您可以选择性地暂存希望作为下一次提交一部分的那些更改,这只会将这些更改添加到暂存区域。
- 您执行一次提交,它将文件按暂存区域中的原样获取,并将该快照永久存储到 Git 目录中。
如果文件的特定版本位于 Git 目录中,则认为该文件已提交。 如果已修改并已将其添加到暂存区域,则会暂存该区域。 如果它在检出后被更改但尚未暂存,则会对其进行修改。
安装Git
Git官网:https://git-scm.com/
Linux安装Git
以 Ubuntu 为例,使用 apt 安装:
sudo apt install git-all以 CentOS 7 为例,使用 yum 安装:
sudo yum install git-allWindows安装Git
在 Windows 上安装 Git 也有几种安装方法。 官方版本可以在 Git 官方网站下载。 打开 https://git-scm.com/download/win,下载会自动开始。 要注意这是一个名为 Git for Windows 的项目(也叫做 msysGit),和 Git 是分别独立的项目;更多信息请访问 http://msysgit.github.io/。
要进行自动安装,你可以使用 Git Chocolatey 包。 注意 Chocolatey 包是由社区维护的。
另一个简单的方法是安装 GitHub Desktop。 该安装程序包含图形化和命令行版本的 Git。 它也能支持 Powershell,提供了稳定的凭证缓存和健全的换行设置。 稍后我们会对这方面有更多了解,现在只要一句话就够了,这些都是你所需要的。 你可以在 GitHub for Windows 网站下载,网址为 GitHub Desktop 网站。
Mac安装Git
在 Mac 上安装 Git 有多种方式。 最简单的方法是安装 Xcode Command Line Tools。 Mavericks (10.9) 或更高版本的系统中,在 Terminal 里尝试首次运行 'git' 命令即可。
要安装 Xcode Command Line Tools,请打开终端并运行以下命令:
xcode-select --install如果没有安装过命令行开发者工具,将会提示你安装。
如果你想安装更新的版本,可以使用二进制安装程序。 官方维护的 macOS Git 安装程序可以在 Git 官方网站下载,网址为 https://git-scm.com/download/mac。
在 Mac 上安装 Git 可以使用 Homebrew。 要安装 Git,请运行以下命令:
brew install git初次运行 Git 前的配置
既然已经在系统上安装了 Git,你会想要做几件事来定制你的 Git 环境。 每台计算机上只需要配置一次,程序升级时会保留配置信息。 你可以在任何时候再次通过运行命令来修改它们。
Git 自带一个 git config 的工具来帮助设置控制 Git 外观和行为的配置变量。 这些变量存储在三个不同的位置:
/etc/gitconfig文件: 包含系统上每一个用户及他们仓库的通用配置。 如果在执行git config时带上--system选项,那么它就会读写该文件中的配置变量。 (由于它是系统配置文件,因此你需要管理员或超级用户权限来修改它。)~/.gitconfig或~/.config/git/config文件:只针对当前用户。 你可以传递--global选项让 Git 读写此文件,这会对你系统上 所有 的仓库生效。- 当前使用仓库的 Git 目录中的
config文件(即.git/config):针对该仓库。 你可以传递--local选项让 Git 强制读写此文件,虽然默认情况下用的就是它。 (当然,你需要进入某个 Git 仓库中才能让该选项生效。)
每一个级别会覆盖上一级别的配置,所以 .git/config 的配置变量会覆盖 /etc/gitconfig 中的配置变量。
在 Windows 系统中,Git 会查找 $HOME 目录下(一般情况下是 C:\Users\$USER )的 .gitconfig 文件。 Git 同样也会寻找 /etc/gitconfig 文件,但只限于 MSys 的根目录下,即安装 Git 时所选的目标位置。 如果你在 Windows 上使用 Git 2.x 以后的版本,那么还有一个系统级的配置文件,Windows XP 上在 C:\Documents and Settings\All Users\Application Data\Git\config,Windows Vista 及其以后的版本在 C:\ProgramData\Git\config。此文件只能以管理员权限通过 git config -f <file> 来修改。
你可以通过以下命令查看所有的配置以及它们所在的文件:
git config --list --show-origin用户信息
安装完 Git 之后,要做的第一件事就是设置你的用户名和邮件地址。 这一点很重要,因为每一个 Git 提交都会使用这些信息,它们会写入到你的每一次提交中,不可更改:
git config --global user.name "John Doe"
git config --global user.email "[email protected]"再次强调,如果使用了 --global 选项,那么该命令只需要运行一次,因为之后无论你在该系统上做任何事情, Git 都会使用那些信息。 当你想针对特定项目使用不同的用户名称与邮件地址时,可以在那个项目目录下运行没有 --global 选项的命令来配置。
很多 GUI 工具都会在第一次运行时帮助你配置这些信息。
检查配置信息
如果想要检查你的配置,可以使用 git config –list 命令来列出所有 Git 当时能找到的配置。
git config --list
# 输出如下
user.name=John Doe
user.email[email protected]
color.status=auto
color.branch=auto
color.interactive=auto
color.diff=auto
...如果看到了重复的变量名,这是因为前面说过会从不同的配置文件获取,当然只有最后找到的配置会生效。
还可以通过 git config <key> 来检查 Git 的某一项配置
git config user.name
# 输出如下
John Doe获取帮助
若你使用 Git 时需要获取帮助,有三种方法可以找到 Git 命令的使用手册:
# <verb>表示一个特定的 Git 命令
git help <verb>
git <verb> --help
man git-<verb>例如,要想获得 config 命令的手册,执行
git help config这些命令很棒,因为你随时随地可以使用而无需联网。 如果你觉得手册或者本书的内容还不够用,你可以尝试在 Freenode IRC 服务器 https://freenode.net 上的 #git 或 #github 频道寻求帮助。 这些频道经常有上百人在线,他们都精通 Git 并且乐于助人。
此外,如果你不需要全面的手册,只需要可用选项的快速参考,那么可以用 -h 选项获得更简明的 ``help'' 输出:
git add -h
# 输出如下
usage: git add [<options>] [--] <pathspec>...
-n, --[no-]dry-run dry run
-v, --[no-]verbose be verbose
-i, --[no-]interactive
interactive picking
-p, --[no-]patch select hunks interactively
-e, --[no-]edit edit current diff and apply
-f, --[no-]force allow adding otherwise ignored files
-u, --[no-]update update tracked files
--[no-]renormalize renormalize EOL of tracked files (implies -u)
-N, --[no-]intent-to-add
record only the fact that the path will be added later
-A, --[no-]all add changes from all tracked and untracked files
--[no-]ignore-removal ignore paths removed in the working tree (same as --no-all)
--[no-]refresh don't add, only refresh the index
--[no-]ignore-errors just skip files which cannot be added because of errors
--[no-]ignore-missing check if - even missing - files are ignored in dry run
--[no-]sparse allow updating entries outside of the sparse-checkout cone
--[no-]chmod (+|-)x override the executable bit of the listed files
--[no-]pathspec-from-file <file>
read pathspec from file
--[no-]pathspec-file-nul
with --pathspec-from-file, pathspec elements are separated with NUL character