函数和指针
函数
在 Go 语言中,函数是一个独立的代码块,用于执行特定的任务或计算。函数可以接收零个或多个参数,并且可以返回零个或多个值。函数的定义包括函数名、参数列表、返回值类型和函数体。
语法格式:
// 定义一个函数的语法格式如下:
func 函数名(参数列表) (返回值列表) {
函数体
}示例:
// 以下定义了一个函数,这个函数没有参数,没有返回值
func printInfo() {
fmt.Println("Hello")
fmt.Println("World")
}函数的命名规范
在 Go 语言的函数命名规范旨在提高代码的可读性和易理解性,并确保代码风格的一致性。遵循良好的命名规范可以使代码更易于维护和理解,尤其是对于大型项目或多人协作开发的项目。
以下是一些 Go 语言函数命名规范的基本原则:
- 使用驼峰命名法(Camel Case):函数名应该由多个单词组成,每个单词的首字母大写,除了第一个单词以外。例如:
GetUserInfo、CalculateAverage等。 - 函数名应该具有描述性:函数名应该清晰地表达函数的功能和用途。避免使用过于笼统或模糊的名称,例如:
doSomething或process。 - 使用动词:函数名通常应该使用动词来表示函数的功能。例如:
GetUserInfo、WriteToFile等。 - 避免缩写:除非是约定俗成的缩写,否则尽量避免在函数名中使用缩写。例如:
useDB优于useDatabase。 - 区分大小写:Go 语言区分大小写,因此函数名中的大小写也应该有意义。例如:
GetUserInfo和getUserInfo是两个不同的函数。 - 包内函数和小写开头:如果函数仅供包内使用,则函数名应该以小写开头。例如:
getUserInfo。如果函数需要供包外访问,则函数名应该以大写开头。例如:GetUser。 - 特殊函数命名:一些特殊类型的函数遵循特定的命名规范,例如:
- 测试函数:通常以
Test开头,后面是所测试的功能或方法的名称。例如,TestGetUserInfo。 - 基准测试函数:通常以
Benchmark开头,后面是所测试的功能或方法的名称。例如,BenchmarkGetUserInfo。 - 示例函数:通常以
Example开头,后面是所演示的功能或方法的名称。例如,ExampleGetUserInfo。
- 测试函数:通常以
- 遵循项目约定:如果项目中存在约定俗成的命名规范,则应遵循项目约定。
函数使用
使用函数时,只需要调用函数名并传递相应的参数。
示例:
package main
import "fmt"
func main() {
// 使用函数
res := add(10, 20)
fmt.Println(res)
}
// 定义一个函数用于计算两个 int 类型的数字之和
func add(a, b int) int {
return a + b
}函数的参数
形式参数:在函数定义时就定义好的参数,用于接收外部传入的数据,叫做形式参数,简称形参。
实际参数:调用函数时,传给形参的实际的数据,叫做实际参数,简称实参。
示例:
package main
import "fmt"
func main() {
// 定义两个变量
p1 := 20
p2 := 30
// 调用函数传入的p1,p2就是实际参数
// 传入的p1就是函数的参数a,传入的p2就是函数的参数b
// 注意事项:实参与形参必须一一对应:顺序,个数,类型
res := add(p1, p2)
fmt.Println(res)
}
// 定义一个函数用于计算两个 int 类型的数字之和
// 定义函数时 a,b 两个就是形式参数
func add(a, b int) int {
return a + b
}package main
import (
"fmt"
)
func main() {
// 调用函数
// 1-10的和
getSum(10)
// 1-50的和
getSum(50)
// 1-100的和
getSum(100)
}
// getSum 定义一个范围求和函数
// 参数n:求和的范围,传入10就是求1-10的和,传入50就是求1-50的和
func getSum(n int) {
sum := 0
for i := 1; i <= n; i++ {
sum += i
}
fmt.Printf("1-%d的和是: %d\n", n, sum)
}在 Go 语言中可变参数函数是一种允许函数接收不定数量参数的方法,使用可变参数可以让函数更加灵活和通用。
语法格式:
// 在函数定义中,通过在参数类型前加上省略号...来表示该参数是可变参数。
func sum(nums ...int) int示例:
/*
这种参数写法是可变参数
add()函数受不定数量的参数,参数的类型全部是int类型
add(1,2,3)
add(4,5,6,7,8)
*/
func add(args ...int) {
sum := 0
for _, v := range args {
sum += v
}
fmt.Println("传入的数值之和:", sum)
}函数返回值
在 Go 语言中通过 return 关键字向外输出返回值。
示例:
func add(a,b int) int {
return a + b
}Go 语言中函数支持多返回值,函数如果有多个返回值时必须用 () 将所有返回值包裹起来。
示例:
func demo(a, b int) (int, int) {
res1 := a + b
res2 := a - b
return res1, res2
}在函数定义时可以给出参起别名,并在函数体中直接使用这些别名,最后通过 return 关键字返回函数的返回值。
示例:
func demo(a, b int) (res1 int, res2 int) {
res1 = a + b
res2 = a - b
return
}可以使用 _ 来忽略不需要的函数返回值。
func foo() (int, int) {
return 1, 2
}
func main() {
// 这个main函数是foo函数的调用方
_, b := foo() // 这里我忽略了foo函数返回的第一个值
}nil 函数
函数也是一种类型,函数变量的默认值是 nil,执行nil函数会引发panic。
示例:
var f func()
// f是一个函数类型,值是nil
// 编译正常,运行报错panic: runtime error: invalid memory address or nil pointer dereference
f()函数的高级用法
在 Go 语言中函数作为一种派生数据类型(复合数据类型),可以看做是一种特殊的变量,用于函数的参数传递和函数的返回值。
- 函数作为另一个函数的实际参数传递:在函数中,我们可以将函数作为参数传递给其他函数。
package main
import "fmt"
func main() {
numbers := []int{1, 2, 3, 4, 5}
// 将 double 函数作为参数传递给 applyOperation 函数
applyOperation(numbers, double)
}
// 定义一个接受函数作为参数的函数
func applyOperation(nums []int, operation func(int) int) {
for _, num := range nums {
result := operation(num)
fmt.Printf("Operation result: %d\n", result)
}
}
// 示例函数:加倍操作
func double(n int) int {
return n * 2
}- 函数作为另一个函数的返回值:在函数中,我们可以将函数作为返回值返回。
package main
import "fmt"
// 返回一个函数的函数
func multiplier(factor int) func(int) int {
// 返回一个闭包函数
return func(n int) int {
return n * factor
}
}
func main() {
// 创建一个乘以 3 的函数
times3 := multiplier(3)
// 使用这个函数来乘以不同的数值
result1 := times3(5) // 5 * 3 = 15
result2 := times3(10) // 10 * 3 = 30
fmt.Println("Result 1:", result1)
fmt.Println("Result 2:", result2)
}init 函数
在Go语言中 init 函数是一种特殊的函数,用于在程序执行开始前,自动执行初始化任务。init 函数没有参数和返回值,并且不能被显式调用或引用。它可以存在于任何包(包括 main 包)中,多个 init 函数可以存在于同一个包中,按照它们声明的顺序依次执行。
特殊和用途:
- 自动执行:init 函数会在程序执行开始前自动调用,无需手动调用。
- 无参数和返回值:init 函数没有参数和返回值。
- 包级别的初始化:每个包可以有多个 init 函数,它们按照声明顺序依次执行,用于执行包级别的初始化任务。
- 执行顺序:对于一个包,其 init 函数的执行顺序是由包引用的依赖关系决定的,先执行被依赖的包的 init 函数。
- 主程序的 main 函数执行前:init 函数通常用于初始化包级别的变量、执行复杂的初始化操作或者注册某些需要在程序运行前执行的逻辑。
示例:
package main
import (
"fmt"
)
func init() {
fmt.Println("Initializing main package...")
}
func init() {
fmt.Println("Initializing again...")
}
func init() {
fmt.Println("Yet another initialization...")
}
func main() {
fmt.Println("Main function started.")
}函数的初始化顺序
我们从程序逻辑结构角度来看,Go 包是程序逻辑封装的基本单元,每个包都可以理解为是一个“自治”的、封装良好的、对外部暴露有限接口的基本单元。一个 Go 程序就是由一组包组成的,程序的初始化就是这些包的初始化。每个 Go 包还会有自己的依赖包、常量、变量、init 函数(其中 main 包有 main 函数)等。
在平时开发中,我们在阅读和理解代码的时候,需要知道这些元素在在程序初始化过程中的初始化顺序,这样便于我们确定在某一行代码处这些元素的当前状态。
下面,我们就通过一张流程图,来了解 Go 包的初始化次序:
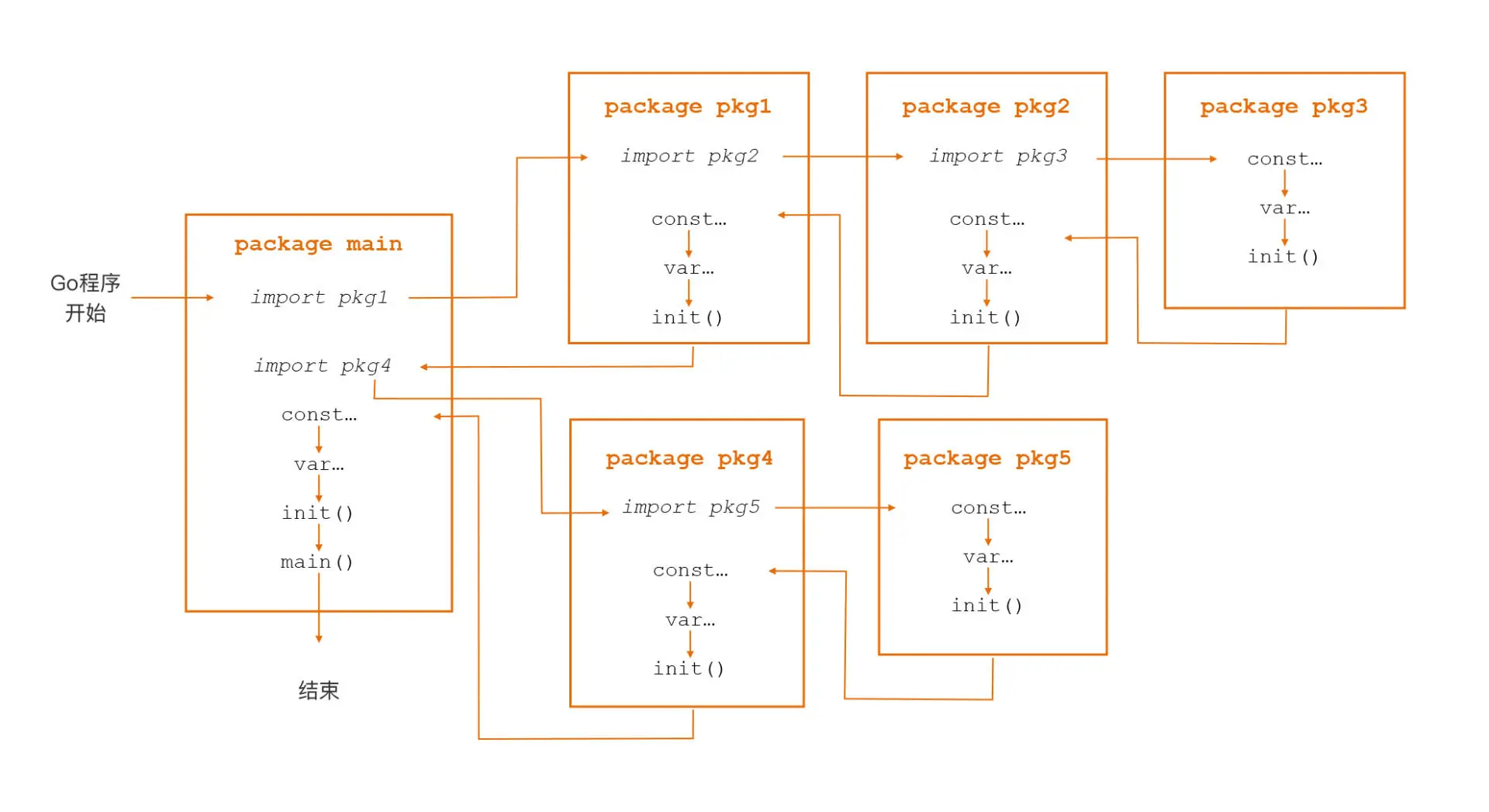
这里,我们来看看具体的初始化步骤。
首先 main 包依赖 pkg1 和 pkg4 两个包,所以第一步,Go 会根据包导入的顺序,先去初始化 main 包的第一个依赖包 pkg1。
第二步 Go 在进行包初始化的过程中,会采用 “深度优先” 的原则,递归初始化各个包的依赖包。在上图里,pkg1 包依赖 pkg2 包,pkg2 包依赖 pkg3 包,pkg3 没有依赖包,于是 Go 在 pkg3 包中按照 “常量 -> 变量 -> init 函数” 的顺序先对 pkg3 包进行初始化;
紧接着,在 pkg3 包初始化完毕后,Go 会回到 pkg2 包并对 pkg2 包进行初始化,接下来再回到 pkg1 包并对 pkg1 包进行初始化。在调用完 pkg1 包的 init 函数后,Go 就完成了 main 包的第一个依赖包 pkg1 的初始化。
接下来,Go 会初始化 main 包的第二个依赖包 pkg4,pkg4 包的初始化过程与 pkg1 包类似,也是先初始化它的依赖包 pkg5,然后再初始化自身;
然后,当 Go 初始化完 pkg4 包后也就完成了对 main 包所有依赖包的初始化,接下来初始化 main 包自身。
最后,在 main 包中,Go 同样会按照 “常量 -> 变量 -> init 函数” 的顺序进行初始化,执行完这些初始化工作后才正式进入程序的入口函数 main 函数。
匿名函数(闭包)
在 Go 语言中,匿名函数是一种没有函数名的函数字面量,也称为闭包(Closure)。它可以在定义的同时被直接调用,或者被赋值给变量后稍后调用。匿名函数通常用于需要临时定义和使用的小型功能块,或者作为函数参数传递给其他函数。
语法格式:
func (参数列表) 返回值 {
// 函数的代码逻辑
}(实际参数)示例:
// 正常的函数
func f1() {
fmt.Println("我是f1()函数...")
}
// 匿名函数,又称为闭包
func () {
fmt.Println("这是一个匿名函数")
}()package main
import "fmt"
func main() {
// 调用f1函数
f1()
// 匿名函数,在main函数中只会执行一次,但是使用函数变量的方式可以执行多次
// 定义一个函数变量
var f2 func()
f2 = func() {
fmt.Println("这是一个匿名函数...")
}
// 打印数据类型
fmt.Printf("f2:%T\n", f2)
// 调用匿名函数
f2()
f2()
// 定义一个有返回类型的匿名函数
res1 := func(a, b int) int {
return a + b
} // 这里并没有传入参数,所以就是将匿名函数赋值给res1变量
fmt.Printf("res1数据类型:%T\n", res1)
res2 := func(a, b int) int {
return a + b
}(5, 6) // 这里传入了参数进行了函数的调用,会将结果的数据赋值给res2
fmt.Printf("res2数据类型:%T\n", res2)
}
// 正常的函数
func f1() {
fmt.Println("这是f1()函数...")
}package main
import "fmt"
// 函数 `process` 接受一个整数和一个回调函数作为参数
func process(num int, callback func(int)) {
// 调用回调函数,将 num 作为参数传递给它
callback(num)
}
func main() {
// 调用 process 函数,传递一个整数和一个匿名函数作为回调
process(10, func(num int) {
fmt.Println("Processing number:", num)
})
}package main
import "fmt"
// 函数 `counter` 返回一个匿名函数
func counter() func() int {
count := 0 // count 是闭包内部的变量
// 返回一个匿名函数,该函数可以访问并修改 count
return func() int {
count++
return count
}
}
func main() {
// 创建一个新的计数器
c1 := counter()
// 使用 c1 调用返回的匿名函数,每次调用 count 增加 1
fmt.Println(c1()) // 输出 1
fmt.Println(c1()) // 输出 2
fmt.Println(c1()) // 输出 3
// 创建另一个新的计数器,它拥有自己的 count 变量
c2 := counter()
// 使用 c2 调用返回的匿名函数,它从 1 开始计数
fmt.Println(c2()) // 输出 1
fmt.Println(c2()) // 输出 2
}匿名函数(闭包)Go语言是支持函数式编程:
- 将匿名函数作为另一个函数的参数,回调函数。
- 将匿名函数作为另一个函数的返回值,可以形成闭包结构。
defer 语句
defer 关键字是 Go 语言中一个强大的工具,用于延迟执行函数调用,实现资源释放、错误处理和性能优化等功能。通过将需要延迟执行的操作放在 defer 语句中,可以保证这些操作会在函数返回前被执行,增加代码的可靠性和可维护性。
defer 在实际开发中经常被使用,例如:
- 资源释放:defer 语句通常用于释放函数使用的各种资源,如文件、数据库连接、锁等。这样可以确保及时释放资源,避免内存泄漏或其他问题。
- 错误处理:defer 可以用于统一处理函数调用过程中出现的错误。
- 日志记录:defer 语句也可用于记录函数的执行时间,用于性能分析和调试。
- 清理工作:defer 还可用于执行各种清理工作,比如关闭数据库连接、关闭窗口等。这对于防止资源泄漏很有帮助。
语法格式:
func main() {
// 这里的defer语句将在main函数返回前执行
defer fmt.Println("World")
fmt.Println("Hello")
}示例:
func readFile(filename string) error {
file, err := os.Open(filename)
if err != nil {
return err
}
defer file.Close()
// 使用bufio.Scanner读取文件内容
scanner := bufio.NewScanner(file)
for scanner.Scan() {
fmt.Println(scanner.Text())
}
if err := scanner.Err(); err != nil {
return err
}
return nil
}func transferMoney(db *sql.DB, fromAccount, toAccount int, amount float64) error {
tx, err := db.Begin()
if err != nil {
return err
}
defer func() {
if p := recover(); p != nil {
tx.Rollback()
panic(p) // 重新抛出panic
} else if err != nil {
tx.Rollback()
} else {
err = tx.Commit()
}
}()
// 执行转账操作
_, err = tx.Exec("UPDATE accounts SET balance = balance - ? WHERE id = ?", amount, fromAccount)
if err != nil {
return err
}
_, err = tx.Exec("UPDATE accounts SET balance = balance + ? WHERE id = ?", amount, toAccount)
if err != nil {
return err
}
return nil
}指针
指针是一种数据类型,用于存储一个变量的内存地址的变量。指针变量的值是变量的地址,而不是变量的值。指针变量可以通过 & 运算符获取变量的地址,并通过 * 运算符获取指针指向的变量的值。
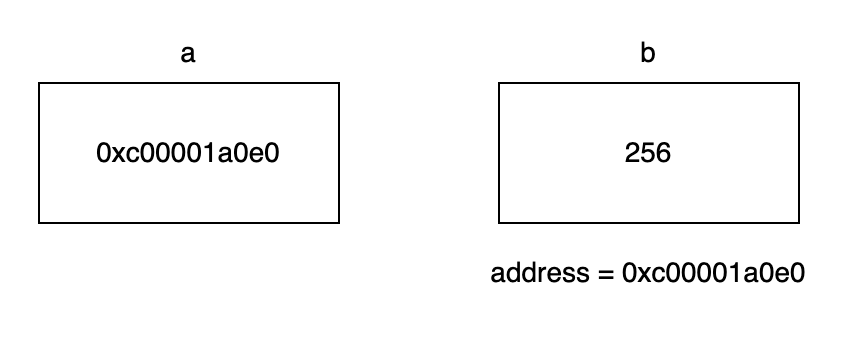
在上面图中,变量b的值为256,存在在内存地址为0xc00001a0e0。变量a的值为0xc00001a0e0,即变量a被认为指向变量b。
语法格式:
var 指针变量名 *数据类型示例:
package main
import "fmt"
func main() {
a := 10
b := &a
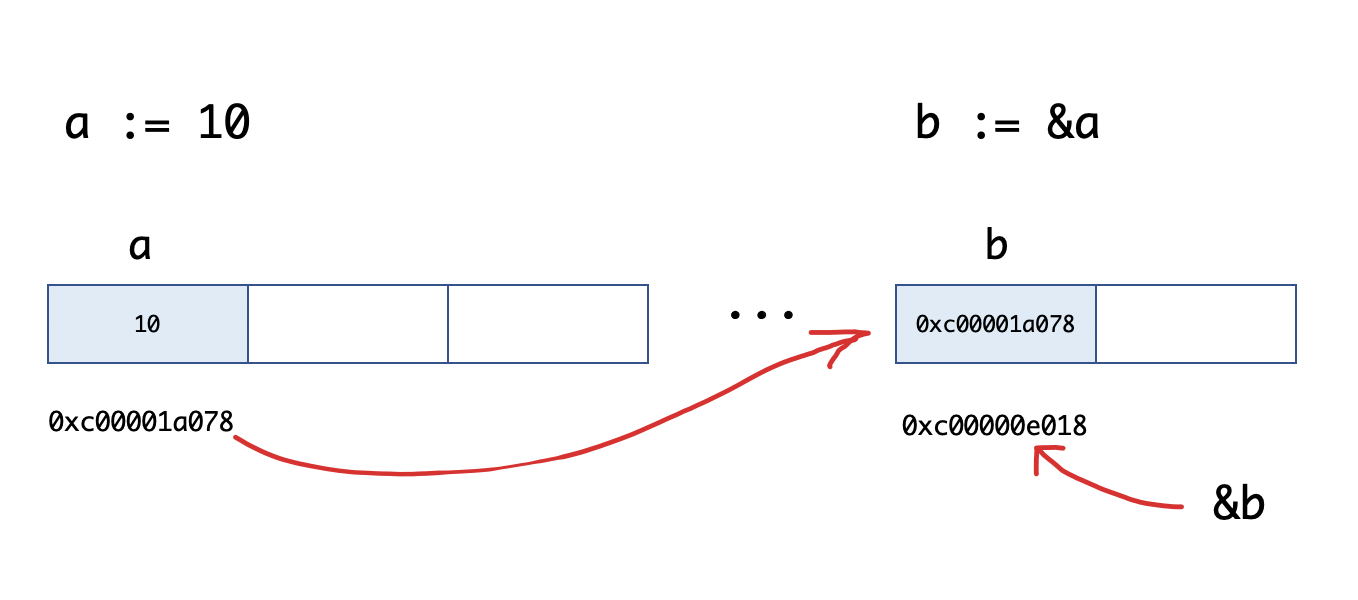
fmt.Printf("a:%d ptr:%p\n", a, &a) // a:10 ptr:0xc00001a078
fmt.Printf("b:%p type:%T\n", b, b) // b:0xc00001a078 type:*int
fmt.Println(&b) // 0xc00000e018
}我们来看一下 b := &a 的图示:
指针的基本用法
获取变量的地址
在 Go 语言中可以通过 & 运算符获取变量的地址。
示例:
package main
import "fmt"
func main() {
// 通过 & 获取变量的内存地址
s1 := "hello"
fmt.Printf("s1的地址值:%p\n", &s1)
}获取指针指向的变量的值
在 Go 语言中可以通过 * 运算符获取指针指向的变量的值。
示例:
package main
import "fmt"
func main() {
// 通过 * 获取指针指向的变量的值
s1 := "hello"
p1 := &s1
fmt.Printf("p1指针指向的变量的值是:%s\n", *p1) // p1指针指向的变量的值是:hello
// 修改指针变量的值
*p1 = "world"
fmt.Printf("s1的值是:%s\n", s1) // s1的值是:world
}空指针
当一个指针被定义后没有分配任何变量时,这个指针的值为 nil 也就是空指针。
示例:
var ptr *int
fmt.Println(ptr == nil) // 输出: true使用new()函数创建指针
在Go语言中 new() 是一个内置的函数,用于动态地分配内存并返回指向该内存的指针。
语法格式:
var 指针变量名 = new(数据类型)指针变量名 := new(数据类型)示例:
// 使用new函数创建一个int类型的指针变量
ptr := new(int)
fmt.Printf("ptr的值是:%v\n", ptr)
fmt.Printf("ptr指向的变量的值是:%v\n", *ptr)
fmt.Printf("ptr自己的内存地址:%v\n", &ptr)使用指针传递函数的参数
当需要在函数内部修改参数的值时,使用指针作为参数是一个很好的选择。使用指针可以直接修改原始数据,而不是只能修改副本。这在需要改变输入数据的场景中非常有用,比如更新数据结构、调整配置参数等。
使用指针作为函数参数的好处包括:
- 可以修改原始数据。
- 减少内存占用。
- 支持空值。
- 增加函数的灵活性。
- 避免副作用。
示例:
package main
import "fmt"
func main() {
x, y := 10, 20
fmt.Println("交换前 x =", x, "y =", y)
swap(&x, &y)
fmt.Println("交换后 x =", x, "y =", y)
}
func swap(a, b *int) {
*a, *b = *b, *a
}package main
import "fmt"
func main() {
numbers := []int{1, 2, 3, 4, 5}
fmt.Println("初始切片:", numbers)
growSlice(&numbers, 3)
fmt.Println("修改长度后切片:", numbers)
}
func growSlice(s *[]int, newLength int) {
*s = (*s)[0:newLength]
}多级指针
多级指针是指向指针的指针,可以有多个层级。在Go语言中,我们可以创建任意级别的指针。这个概念虽然不常用,但在某些特定场景下非常有用。
示例:
// 定义一个int类型变量a
a := 10
fmt.Printf("a的值是%d,a的内存地址是:%p\n", a, &a) // a = 10
// 定义一个指针变量p1,指向变量a
p1 := &a
fmt.Printf("p1的数据类型是:%T,p1存储的值是:%v,p1的内存地址是:%p\n", p1, p1, &p1)
// 二级指针 这里存储的值是一级指针的内存地址 &p1
p2 := &p1
fmt.Printf("p2的数据类型是:%T,p2存储的值是:%v,p2的内存地址是:%p\n", p2, p2, &p2)
// 三级指针 这里存储的值是二级指针的内存地址 &p2
p3 := &p2
fmt.Printf("p3的数据类型是:%T,p3存储的值是:%v,p3的内存地址是:%p\n", p3, p3, &p3)
// 修改三级指针指向的变量存储的值
***p3 = 111
fmt.Printf("a的值是:%d\n", a) // a = 111